TL;DR We propose an unsupervised approach to identify interpretable directions in text-to-image diffusion models, such as Stable Diffusion. Our method finds semantically meaningful directions across various domains like faces, cats, and art.

NoiseCLR can apply multiple directions either within a single domain (a) or across different domains in the same image (b, c) in a disentangled manner. Since the directions learned by our model are highly disentangled, there is no need for semantic masks or user-provided guidance to prevent edits in different domains from influencing each other. Additionally, our method does not require fine-tuning or retraining of the diffusion model, nor does it need any labeled data to learn directions. Note that our method does not require any text prompts, the direction names above are provided by us for easy understanding.
Abstract
Generative models have been very popular in the recent years for their image generation capabilities. GAN-based models are highly regarded for their disentangled latent space, which is a key feature contributing to their success in controlled image editing. On the other hand, diffusion models have emerged as powerful tools for generating high-quality images. However, the latent space of diffusion models is not as thoroughly explored or understood. Existing methods that aim to explore the latent space of diffusion models usually relies on text prompts to pinpoint specific semantics. However, this approach may be restrictive in areas such as art, fashion, or specialized fields like medicine, where suitable text prompts might not be available or easy to conceive thus limiting the scope of existing work. In this paper, we propose an unsupervised method to discover latent semantics in text-to-image diffusion models without relying on text prompts. Our method takes a small set of unlabeled images from specific domains, such as faces or cats, and a pre-trained diffusion model, and discovers diverse semantics in unsupervised fashion using a contrastive learning objective. Moreover, the learned directions can be applied simultaneously, either within the same domain (such as various types of facial edits) or across different domains (such as applying cat and face edits within the same image) without interfering with each other. Our extensive experiments show that our method achieves highly disentangled edits, outperforming existing approaches in both diffusion-based and GAN-based latent space editing methods.
Method
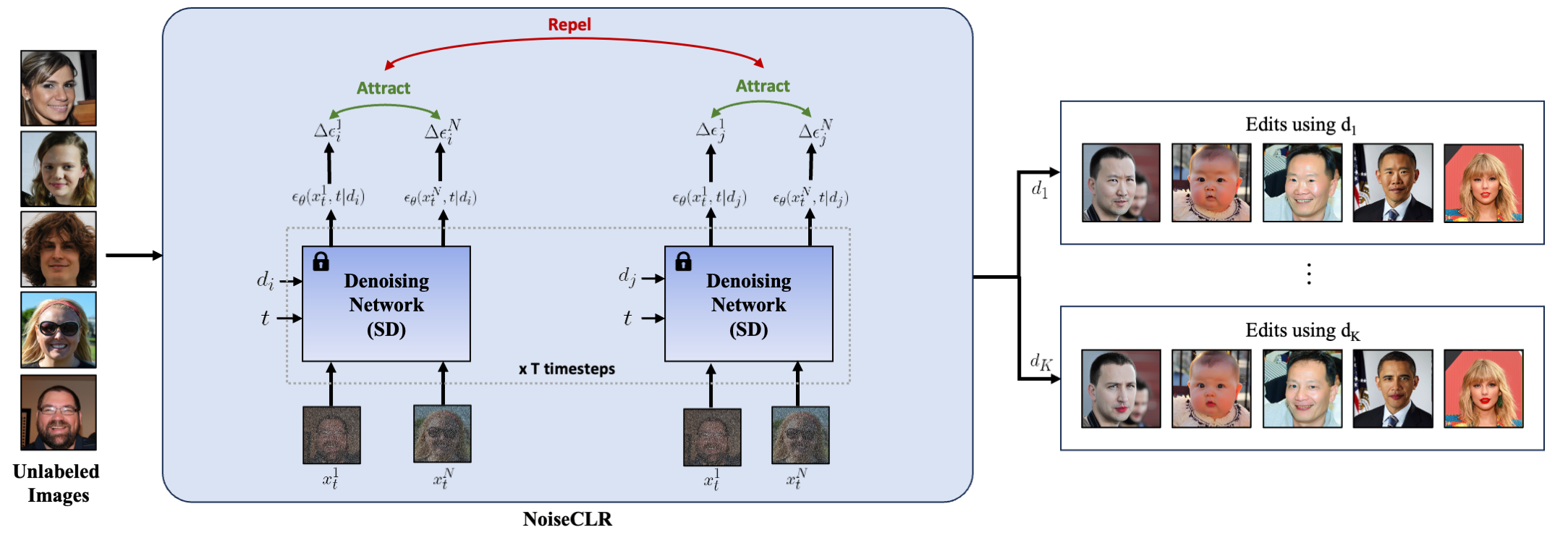
NoiseCLR employs a contrastive objective to learn latent directions in an unsupervised manner. Our method utilizes the insight that similar edits in the noise space should attract to each other, whereas edits made by different directions should be repelled from each other. Given N unlabeled images from an particular domain such as facial images, we first apply the forward diffusion process for t timesteps. Then, by using the noised variables {x1, ..., xN}, we apply the denoising step, conditioning this step with the learned latent directions. Our method discovers K latent directions d1,...,dK for a pretrained denoising network such as Stable Diffusion, where directions correspond to semantically meaningful edits such as adding a lipstick.
Discovered Directions
Results on Face Domain

Edits are performed using the directions learned by our method in an unsupervised manner. We annotate the discovered directions above for the sake of understandability. The edits learned by our method are both effective in domain examples (e.g. human faces) and out-of-domain images (e.g. paintings).
Results on Different Domains

To demonstrate the generalizability of our method across different domains, we provide editing results on artistic paintings, cats and cars. As demonstrated from in the editing results, our method is able to learn and apply latent directions from various domains using a single diffusion model.
Composition Results
Since NoiseCLR can learn latent directions from different domains within the shared latent space of Stable Diffusion, it is capable of executing both intra-domain and inter-domain edits.

Our method can find domain-specific edits that can be composed either a) intra-domain where edits from the same domain can be applied simultaneously, b) cross-domain, where edits from different domains can be combined and applied simultaneously.
BibTeX
@misc{dalva2023noiseclr,
title={NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models},
author={Yusuf Dalva and Pinar Yanardag},
year={2023},
eprint={2312.05390},
archivePrefix={arXiv},
primaryClass={cs.CV}
}